

学习自下的回答,本内容为阅读对应资料后的笔记和自己的理解: Why does Directory traversal attack %C0%AF work?
基础知识
bits:组成bytes,是最小的单位
bytes:由8个bits组成。
URL编码
URL编码-
- 也叫百分比编码(https://en.wikipedia.org/wiki/Percent-encoding)
- 组成:%xx ,其中x代表一个十六进制的数字,能代表0-255内的数字
- %xx代表一个byte
%C0%2F:对应十进制192 (1100 0000) 和175 (1010 1111),
%C0%AF:对应十进制的192 (1100 0000)和47 (0010 1111)
关于ASCII
ASCII 定义了0-127下的byte代表的的符号
ASCII 的扩展:unicode编码,以允许特殊符号(for non-English writers)
Unicode
Unicode下特殊字符被数字编码替代。
Unicode进入字节流需要:
- UTF-8编码
- ASCII in a single byte (8 bits 0-127)
UTF-8编码下:
110x xxxx 代表2 bytes (values 在:128-2047)
1110 xxxx 代表3 bytes
1111 xxxx 代表4 bytes
在UTF-8对于2bytes的字符的格式定义见下图第二行:
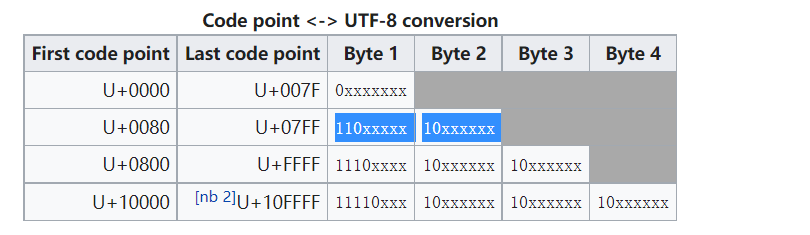
%C0%AF是在范围外的数字:%AF(0010 1111) 与格式10xxxxxx不符。所以%C0%AF应该在UTF-8中视为报错。然而UTF-8为了速度”快“的设计忽略了安全方面。所以有的库不会检查two-byte的编码的值是否在有效范围内(即使unicode标准禁止这个)。
许多网站并不检查第二个byte的首个bit是否是1,因为前一个byte已经表明了该字符有2byte的codepoint。
错误的解码会接受110i jklm ??no pqrs 作为有两个byte的codepoint,而忽视掉10也是UTF-8的标准
所以,现在我们知道了为什么%C0%AF和%C0%2F都能最终被unicode 解码器解码为符号/ 的原因是跳过了合适的检查。
至于为什么能够成功的实现目录遍历,通常是发生在过滤不当输入和解码unicode符号发生在服务器的不同层级。
如果,服务器提供文件并且完成解码 是在防止目录遍历的检查后的;或操作系统的差异有略不同的处理,攻击者就能够跳过过滤让攻击生效。
